Jul 29, 2021 | Korea, Science and Policy, Young Scientists
By Fanni Daniella Szakal, 2021 IIASA Science Communication Fellow
Despite the political challenges, 2021 YSSP participant Eunbeen Park is researching ways to restore forests in isolated North Korea.

© Znm | Dreamstime.com
North Korea is somewhat of an enigma and getting a glimpse into what transpires behind its borders is a difficult task. Based on our limited information, it however seems that its once luscious forests have disappeared at an alarming rate in the last few decades.
Deforestation in North Korea is fueled by economic difficulties, climate change, and a lack of information for effective forest management. As forests are recognized as important carbon sinks that are invaluable when working towards the climate goals established in the Paris Agreement, finding a way to restore them is imperative. Forests are also essential in solving food insecurity and energy issues, which is especially relevant in the face of the current economic hardship in North Korea.
Neighboring South Korea serves as a benchmark for a successful reforestation campaign after having restored most of its forest cover in the last half a century. South Korean researchers and NGOs are keen to support afforestation efforts in North Korea and it seems that the North Korean government is also prioritizing this through a 10-year plan announced by North Korean leader Kim Jong-Un in 2015. The strained relationship between the two Koreas however, often hinders effective collaboration.
‘’We are close to North Korea regionally, but direct connection is difficult for political reasons. However, many researchers are interested in studying North Korea and there are currently many projects for South and North Korea collaboration supported by the Ministry of Unification,” says Eunbeen Park, a participant in the 2021 Young Scientists Summer Program and a second year PhD student in Environmental Planning and Landscape Architecture at Korea University in Seoul, South Korea.

North Korean countryside © Znm|Dreamstime.com
Modeling afforestation scenarios in North Korea
Park specializes in using remote sensing data for environmental monitoring and detecting changes in land cover. During her time at IIASA, she will use the Agriculture, Forestry, and Ecosystem Services Land Modeling System (AFE-LMS) developed by IIASA to support forest restoration in North Korea.
First, Park will use land cover maps dating back to the 1980s to map the change in forest cover. She will then identify areas for potential afforestation considering land cover change, forest productivity, climate, and different environmental variables, such as soil type. She will also develop different afforestation scenarios based on forest management options and the tree species used.
According to Andrey Krasovskiy, Park’s supervisor at IIASA, when selecting tree species for afforestation we need to take into account their economic, environmental, and recreational values.
“From a set of around 10 species we need to choose those that would be the most suitable in terms of resilience to climate change and to disturbances such as fire and beetles,” he says.
Challenges in data collection
A major challenge in Park’s research is obtaining accurate information for building her models. If there is relevant research from North Korea, it is not available to foreign researchers and without being able to enter the country to collect field data in person, her research has to rely on remote sensing data or data extrapolated from South Korean studies.
Fortunately, in recent years, remote sensing technology has evolved to provide high-resolution satellite data through which we are able to take a thorough look at the land cover of the elusive country. Park will match these maps with yield tables provided by Korea University based on South Korean data. As the ecology of the two Koreas are largely similar, these maps are thought to provide accurate results.
Is there space for science diplomacy?
“Research shouldn’t have any boundaries,” notes Krasovskiy. “In reality however, the lack of scientific collaboration between research groups in South and North Korea poses a major obstacle in turning this research into policy. Luckily, some organizations, such as the Hanns Seidel Foundation in South Korea, are able to bridge the gap and organize joint activities that provide hope for a more collaborative future.”
Despite the diplomatic hurdles, Park hopes that her work will find its way to North Korean policymakers.
“I expect my research might make a contribution to help policymakers and scientific officials establish forest relevant action in North Korea,” she concludes.
Jul 1, 2021 | Biodiversity, Climate Change, Ecosystems
By Florian Hofhansl, researcher in the Biodiversity, Ecology, and Conservation Research Group of the IIASA Biodiversity and Natural Resources Program
Florian Hofhansl writes about a successful paper on which he was the lead author that was recently ranked #32 on the list of the Top 100 most downloaded ecology papers published in 2020.
Early in 2020, one of my manuscripts titled “Climatic and edaphic controls over tropical forest diversity and vegetation carbon storage” was accepted for publication in the prestigious journal Nature Scientific Reports.
Initially, I was worried about the bad timing when I was informed that the paper would be published on 19 March – right at the onset of the COVID-19 pandemic – since it took me and my colleagues almost a decade to collect the data and publish our results on the biodiversity and functioning of tropical forest ecosystems.
 However, my worries completely disappeared when I learned that our research article had received more that 3,000 downloads, placing it among the top 100 downloaded ecology papers for Scientific Reports in 2020. This is an extraordinary achievement considering that Scientific Reports published more than 500 ecology papers in 2020. Seeing our paper positioned at #32 of the top 100 most downloaded articles in the field, therefore meant that our science was of real value to the research community.
However, my worries completely disappeared when I learned that our research article had received more that 3,000 downloads, placing it among the top 100 downloaded ecology papers for Scientific Reports in 2020. This is an extraordinary achievement considering that Scientific Reports published more than 500 ecology papers in 2020. Seeing our paper positioned at #32 of the top 100 most downloaded articles in the field, therefore meant that our science was of real value to the research community.
We kicked off our study in the dry-season of 2011 by selecting twenty one-hectare forest inventory plots at the beautiful Osa peninsula – one of the last remnants of continuous primary forest – located in southwestern Costa Rica. We did not expect that our project would receive this much scientific recognition as we were merely interested in describing the stunning biodiversity of this remote tropical region. Nevertheless, we were striving to understand the functioning of the area’s megadiverse ecosystem by conducting repeated measurements of forest characteristics, such as forest growth, tree mortality, and plant species composition.
After periodically revisiting the permanent inventory plots, and recording data for almost a decade, we found stark differences in the composition of tropical plant species such as trees, palms, and lianas across the landscape. Most interestingly, these different functional groups follow different strategies in their competition for light and nutrients, both limiting plant growth in the understory of a tropical rainforest. For instance, lianas – which are long-stemmed, woody vines – are relatively fast growing and try to reach the canopy to get to the sunlight, but they do not store as much carbon as a tree stem to reach the same height in the canopy. In contrast, palms share a different strategy and mostly stay in the lower sections of the forest where they collect water and nutrients with their bundles of palm leaves arranged upward to catch droplets and nutrients falling from above, thus reducing local resource limitation.

Lead author Florian Hofhansl and field botanist, Eduardo Chacon-Madrigal got stuck between roots of the walking palm (Socratea exorrhiza), while surveying one of the twenty one-hectare permanent inventory plots © Florian Hofhansl
Our results indicate that each plant functional group – that is, a collection of organisms (i.e., trees, palms, or lianas) that share the same characteristics – was associated with specific climate conditions and distinct soil properties across the landscape. Hence, this finding indicates that we would have to account for the small-scale heterogeneity of the landscape in order to understand future ecosystem responses to projected climate change, and thus to accurately predict associated tropical ecosystem services under future scenarios.
Our study and its subsequent uptake by the research community, illustrates the value of conducting on-site experiments that empower researchers to understand crucial ecosystem processes and applying these results in next-generation models. Research like this makes it possible for scientists to evaluate vegetation–atmosphere feedbacks and thus determine how much of man-made emissions will remain in the atmosphere and therefore might further heat up the climate system in the future.
Our multidisciplinary research project furthermore highlighted that it is crucial to gather knowledge from multiple disciplines, such as botany (identifying species), plant ecology (identifying functional strategies), and geology (identifying differences in parent material and soil types) – since all of these factors need to be considered in concert to capture the complexity of any given system, when aiming to understand the systematic response to climate change.
Read more about the research here: https://tropicalbio.me/blog
Reference:
Hofhansl F, Chacón-Madrigal E, Fuchslueger L, Jenking D, Morera A, Plutzar C, Silla F, Andersen K, et al. (2020). Climatic and edaphic controls over tropical forest diversity and vegetation carbon storage. Scientific Reports DOI: 10.1038/s41598-020-61868-5 [pure.iiasa.ac.at/16360]
Note: This article gives the views of the author, and not the position of the Nexus blog, nor of the International Institute for Applied Systems Analysis.
Sep 23, 2020 | Alumni, Data and Methods, Environment, IIASA Network
By Victor Maus, alumnus of the IIASA Ecosystems Services and Management Program and researcher at the Vienna University of Economics and Business
The mining of coal, metals, and other minerals causes loss of natural habitats across the entire globe. However, available data is insufficient to measure the extent of these impacts. IIASA alumnus Victor Maus and his colleagues mapped more than 57,000 km² of mining areas over the whole world using satellite images.

© Pix569 | Dreamstime.com
Our modern lifestyles and consumption patterns cause environmental and social impacts geographically displaced in production sites thousands of kilometres away from where the raw materials are extracted. Complex supply chains connecting mineral mining regions to consumers often obscure these impacts. Our team at the Vienna University of Economics and Business is investigating these connections and associated impacts on a global-scale www.fineprint.global.
However, some mining impacts are not well documented across the globe, for example, where and how much area is used to extract metals, coal, and other essential minerals are unknown. This information is necessary to assess the environmental implications, such as forest and biodiversity loss associated with mining activities. To cover this data gap, we analyzed the satellite images of more than 6,000 known mining regions all around the world.
Visually identifying such a large number of mines in these images is not an easy task. Imagine you are flying and watching from the window of a plane, how many objects on the Earth’s surface can you identify and how fast? Using satellite images, we searched and mapped mines over the whole globe. It was a very time-consuming and exhausting task, but we also learned a lot about what is happening on the ground. Besides, it was very interesting to virtually visit a vast range of mining places across the globe and realize the large variety of ecosystems that are affected by our increasing demand for nature’s resources.
The result of our adventure is a global data set covering more than 21,000 mapped areas adding up to around 57,000 km² (that is about the size of Croatia or Togo). These mapped areas cover open cuts, tailings dams, piles of rocks, buildings, and other infrastructures related to the mining activities — some of them extending to almost 10 km (see figure below). We also learned that around 50 % of the mapped mining area is concentrated in only five countries, China, Australia, the United States, Russia, and Chile.
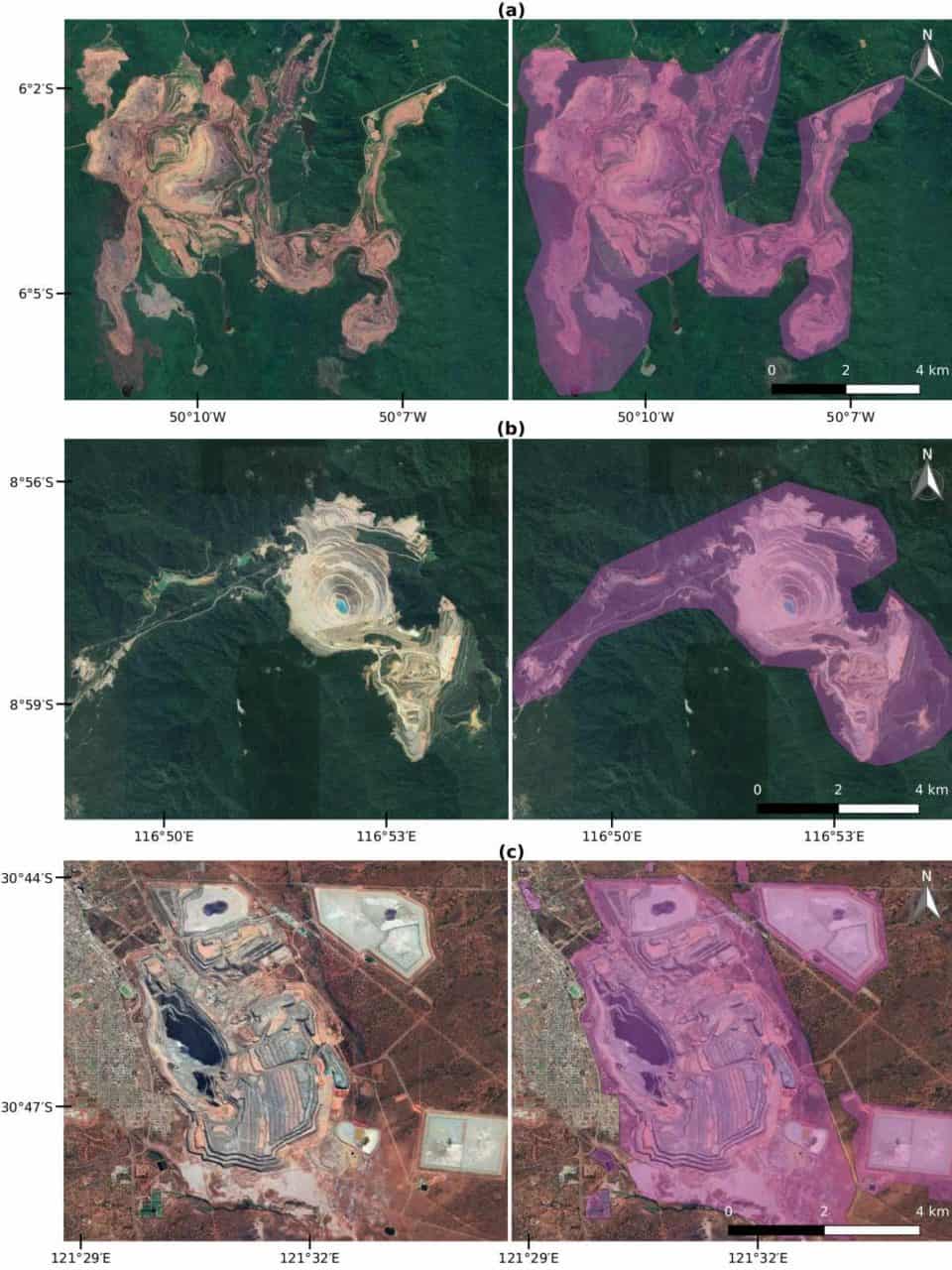
Examples of mines viewed from Google Satellite images. (a) Caraj\'{a}s iron ore mine in Brazil, (b) Batu Hijau copper-gold mine in Indonesia, and (c) Super Pit gold mine in Australia. In purple is the data collected for these mines (Figure source: www.nature.com/articles/s41597-020-00624-w).
Using these data, we can improve the calculation of environmental indicators of global mineral extraction and thus support the development of less harmful ways to extract natural resources. Further, linking these impacts to supply chains can help to answer questions related to our consumption of goods. For example, which impacts the extraction of minerals used in our smartphones cases and where on the planet they occur? We hope that many others will use the mining areas data for their own research and applications. Therefore, the data is fully open to everyone. You can explore the global mining areas using our visualization tool at www.fineprint.global/viewer or you can download the full data set from doi.pangaea.de/10.1594/PANGAEA.910894. The complete description of the data and methods is in our paper available from www.nature.com/articles/s41597-020-00624-w.
This blog post first appeared on the Springer Nature “Behind the paper” website. Read the original post here.
Note: This article gives the views of the authors, and not the position of the Nexus blog, nor of the International Institute for Applied Systems Analysis.
Aug 11, 2020 | COVID19, Data and Methods, Science and Policy, Women in Science
By Sibel Eker, researcher in the IIASA Energy Program
IIASA researcher Sibel Eker explores the usefulness and reliability of COVID-19 models for informing decision making about the extent of the epidemic and the healthcare problem.

© zack Ng 99 | Dreamstime.com
In the early days of the COVID-19 pandemic, when facts were uncertain, decisions were urgent, and stakes were very high, both the public and policymakers turned not to oracles, but to mathematical modelers to ask how many people could be infected and how the pandemic would evolve. The response was a plethora of hypothetical models shared on online platforms and numerous better calibrated scientific models published in online repositories. A few such models were announced to support governments’ decision-making processes in countries like Austria, the UK, and the US.
With this announcement, a heated debate began about the accuracy of model projections and their reliability. In the UK, for instance, the model developed by the MRC Centre for Global Infectious Disease Analysis at Imperial College London projected around 500,000 and 20,000 deaths without and with strict measures, respectively. These different policy scenarios were misinterpreted by the media as a drastic variation in the model assumptions, and hence a lack of reliability. In the US, projections of the model developed by the University of Washington’s Institute for Health Metrics and Evaluation (IHME) changed as new data were fed into the model, sparking further debate about the accuracy thereof.
This discussion about the accuracy and reliability of COVID-19 models led me to rethink model validity and validation. In a previous study, my colleagues and I showed that, based on a vast scientific literature on model validation and practitioners’ views, validity often equates with how good a model represents the reality, which is often measured by how accurately the model replicates the observed data. However, representativeness does not always imply the usefulness of a model. A commentary following that study emphasized the tradeoff between representativeness and the propagation error caused by it, thereby cautioning against an exaggerated focus on extending model boundaries and creating a modeling hubris.
Following these previous studies, in my latest commentary in Humanities and Social Sciences Communications, I briefly reviewed the COVID-19 models used in public policymaking in Austria, the UK, and the US in terms of how they capture the complexity of reality, how they report their validation, and how they communicate their assumptions and uncertainties. I concluded that the three models are undeniably useful for informing the public and policy debate about the extent of the epidemic and the healthcare problem. They serve the purpose of synthesizing the best available knowledge and data, and they provide a testbed for altering our assumptions and creating a variety of “what-if” scenarios. However, they cannot be seen as accurate prediction tools, not only because no model is able to do this, but also because these models lacked thorough formal validation according to their reports in late March. While it may be true that media misinterpretation triggered the debate about accuracy, there are expressions of overconfidence in the reporting of these models, even though the communication of uncertainties and assumptions are not fully clear.

© Jaka Vukotič | Dreamstime.com
The uncertainty and urgency associated with pandemic decision-making is familiar to many policymaking situations from climate change mitigation to sustainable resource management. Therefore, the lessons learned from the use of COVID models can resonate in other disciplines. Post-crisis research can analyze the usefulness of these models in the discourse and decision making so that we can better prepare for the next outbreak and we can better utilize policy models in any situation. Until then, we should take the prediction claims of any model with caution, focus on the scenario analysis capability of models, and remind ourselves one more time that a model is a representation of reality, not the reality itself, like René Magritte notes that his perfectly curved and brightly polished pipe is not a pipe.
References
Eker S (2020). Validity and usefulness of COVID-19 models. Humanities and Social Sciences Communications 7 (1) [pure.iiasa.ac.at/16614]
Note: This article gives the views of the author, and not the position of the Nexus blog, nor of the International Institute for Applied Systems Analysis.
Mar 29, 2019 | USA, Young Scientists
By Matt Cooper, PhD student at the Department of Geographical Sciences, University of Maryland, and 2018 winner of the IIASA Peccei Award
I never pictured myself working in Europe. I have always been an eager traveler, and I spent many years living, working and doing fieldwork in Africa and Asia before starting my PhD. I was interested in topics like international development, environmental conservation, public health, and smallholder agriculture. These interests led me to my MA research in Mali, working for an NGO in Nairobi, and to helping found a National Park in the Philippines. But Europe seemed like a remote possibility. That was at least until fall 2017, when I was looking for opportunities to get abroad and gain some research experience for the following summer. I was worried that I wouldn’t find many opportunities, because my PhD research was different from what I had previously done. Rather than interviewing farmers or measuring trees in the field myself, I was running global models using data from satellites and other projects. Since most funding for PhD students is for fieldwork, I wasn’t sure what kind of opportunities I would find. However, luckily, I heard about an interesting opportunity called the Young Scientists Summer Program (YSSP) at IIASA, and I decided to apply.
Participating in the YSSP turned out to be a great experience, both personally and professionally. Vienna is a wonderful city to live in, and I quickly made friends with my fellow YSSPers. Every weekend was filled with trips to the Alps or to nearby countries, and IIASA offers all sorts of activities during the week, from cultural festivals to triathlons. I also received very helpful advice and research instruction from my supervisors at IIASA, who brought a wealth of experience to my research topic. It felt very much as if I had found my kind of people among the international PhD students and academics at IIASA. Freed from the distractions of teaching, I was also able to focus 100% on my research and I conducted the largest-ever analysis of drought and child malnutrition.

© Matt Cooper
Now, I am very grateful to have another summer at IIASA coming up, thanks to the Peccei Award. I will again focus on the impact climate shocks like drought have on child health. however, I will build on last year’s research by looking at future scenarios of climate change and economic development. Will greater prosperity offset the impacts of severe droughts and flooding on children in developing countries? Or does climate change pose a hazard that will offset the global health gains of the past few decades? These are the questions that I hope to answer during the coming summer, where my research will benefit from many of the future scenarios already developed at IIASA.
I can’t think of a better research institute to conduct this kind of systemic, global research than IIASA, and I can’t picture a more enjoyable place to live for a summer than Vienna.
Note: This article gives the views of the author, and not the position of the Nexus blog, nor of the International Institute for Applied Systems Analysis.



You must be logged in to post a comment.